MySQL 死锁了,怎么办?
MySQL 死锁了,怎么办?
说个很早之前自己遇到过数据库死锁问题。
有个业务主要逻辑就是新增订单、修改订单、查询订单等操作。然后因为订单是不能重复的,所以当时在新增订单的时候做了幂等性校验,做法就是在新增订单记录之前,先通过 select ... for update 语句查询订单是否存在,如果不存在才插入订单记录。
而正是因为这样的操作,当业务量很大的时候,就可能会出现死锁。
接下来跟大家聊下为什么会发生死锁,以及怎么避免死锁。
死锁的发生
本次案例使用存储引擎 Innodb,隔离级别为可重复读(RR)。
接下来,我用实战的方式来带大家看看死锁是怎么发生的。
我建了一张订单表,其中 id 字段为主键索引,order_no 字段普通索引,也就是非唯一索引:
CREATE TABLE `t_order` (
`id` int NOT NULL AUTO_INCREMENT,
`order_no` int DEFAULT NULL,
`create_date` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `index_order` (`order_no`) USING BTREE
) ENGINE=InnoDB ;
然后,先 t_order 表里现在已经有了 6 条记录:
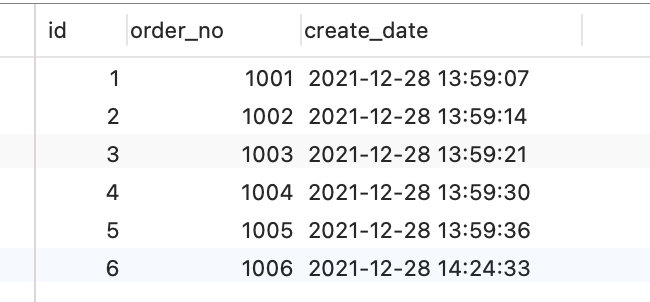
假设这时有两事务,一个事务要插入订单 1007,另外一个事务要插入订单 1008,因为需要对订单做幂等性校验,所以两个事务先要查询该订单是否存在,不存在才插入记录,过程如下:

可以看到,两个事务都陷入了等待状态(前提没有打开死锁检测),也就是发生了死锁,因为都在相互等待对方释放锁。
这里在查询记录是否存在的时候,使用了 select ... for update 语句,目的为了防止事务执行的过程中,有其他事务插入了记录,而出现幻读的问题。
如果没有使用 select ... for update 语句,而使用了单纯的 select 语句,如果是两个订单号一样的请求同时进来,就会出现两个重复的订单,有可能出现幻读,如下图:

为什么会产生死锁?
可重复读隔离级别下,是存在幻读的问题。
Innodb 引擎为了解决「可重复读」隔离级别下的幻读问题,就引出了 next-key 锁,它是记录锁和间隙锁的组合。
- Record Lock,记录锁,锁的是记录本身;
- Gap Lock,间隙锁,锁的就是两个值之间的空隙,以防止其他事务在这个空隙间插入新的数据,从而避免幻读现象。
普通的 select 语句是不会对记录加锁的,因为它是通过 MVCC 的机制实现的快照读,如果要在查询时对记录加行锁,可以使用下面这两个方式:
begin;
//对读取的记录加共享锁
select ... lock in share mode;
commit; //锁释放
begin;
//对读取的记录加排他锁
select ... for update;
commit; //锁释放
行锁的释放时机是在事务提交(commit)后,锁就会被释放,并不是一条语句执行完就释放行锁。
比如,下面事务 A 查询语句会锁住 (2, +∞] 范围的记录,然后期间如果有其他事务在这个锁住的范围插入数据就会被阻塞。
next-key 锁的加锁规则其实挺复杂的,在一些场景下会退化成记录锁或间隙锁,我之前也写一篇加锁规则,详细可以看这篇:MySQL 是怎么加锁的?
需要注意的是,如果 update 语句的 where 条件没有用到索引列,那么就会全表扫描,在一行行扫描的过程中,不仅给行记录加上了行锁,还给行记录两边的空隙也加上了间隙锁,相当于锁住整个表,然后直到事务结束才会释放锁。
所以在线上千万不要执行没有带索引条件的 update 语句,不然会造成业务停滞,我有个读者就因为干了这个事情,然后被老板教育了一波,详细可以看这篇:update 没加索引会锁全表?
回到前面死锁的例子。
事务 A 在执行下面这条语句的时候:
select id from t_order where order_no = 1007 for update;
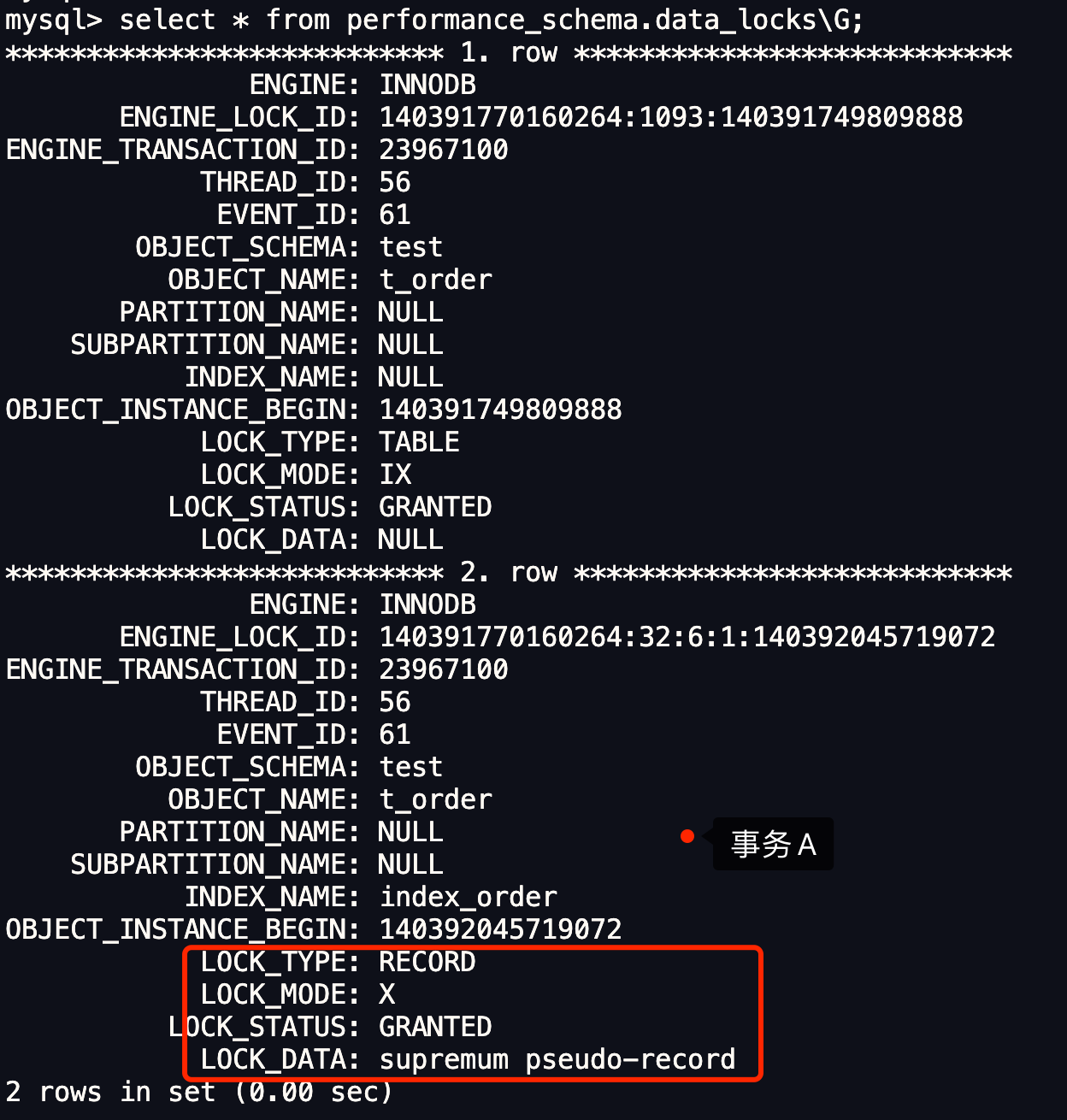
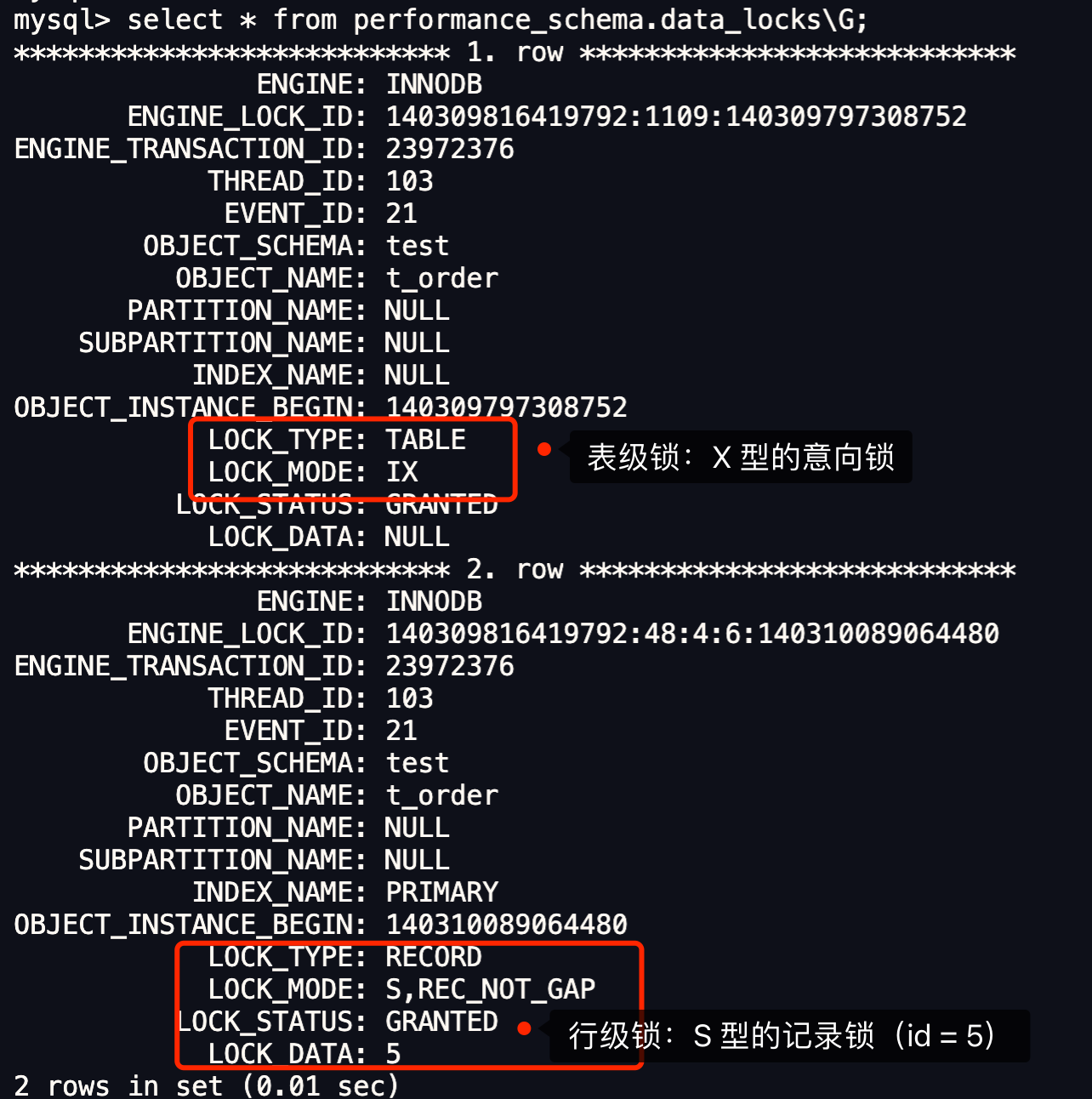
我们可以通过 select * from performance_schema.data_locks\G; 这条语句,查看事务执行 SQL 过程中加了什么锁。
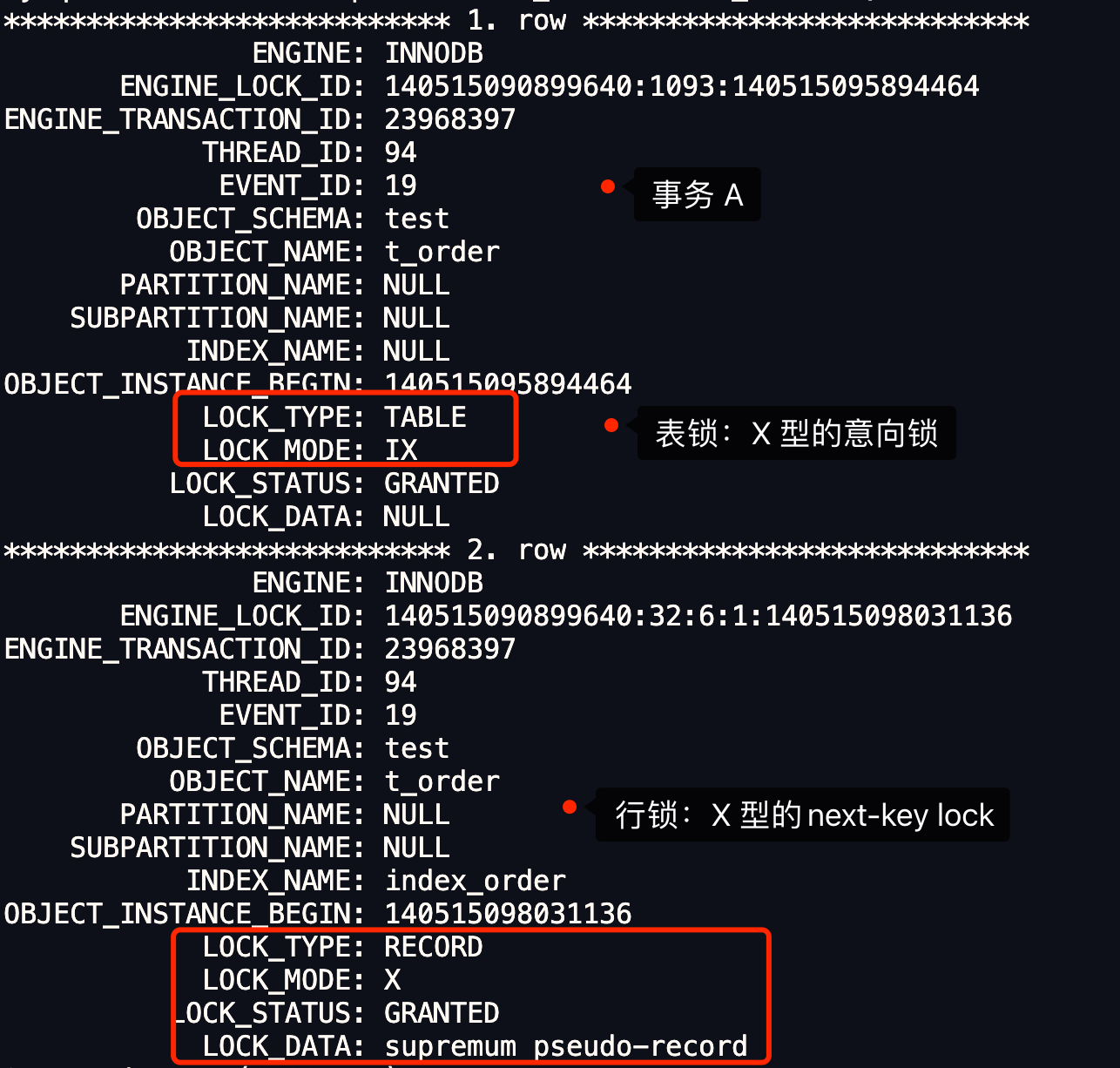
从上图可以看到,共加了两个锁,分别是:
- 表锁:X 类型的意向锁;
- 行锁:X 类型的 next-key 锁;
这里我们重点关注行锁,图中 LOCK_TYPE 中的 RECORD 表示行级锁,而不是记录锁的意思,通过 LOCK_MODE 可以确认是 next-key 锁,还是间隙锁,还是记录锁:
- 如果 LOCK_MODE 为
X,说明是 X 型的 next-key 锁; - 如果 LOCK_MODE 为
X, REC_NOT_GAP,说明是 X 型的记录锁; - 如果 LOCK_MODE 为
X, GAP,说明是 X 型的间隙锁;
因此,此时事务 A 在二级索引(INDEX_NAME : index_order)上加的是 X 型的 next-key 锁,锁范围是(1006, +∞]。
next-key 锁的范围 (1006, +∞],是怎么确定的?
根据我的经验,如果 LOCK_MODE 是 next-key 锁或者间隙锁,那么 LOCK_DATA 就表示锁的范围最右值,此次的事务 A 的 LOCK_DATA 是 supremum pseudo-record,表示的是 +∞。然后锁范围的最左值是 t_order 表中最后一个记录的 index_order 的值,也就是 1006。因此,next-key 锁的范围 (1006, +∞]。
提示
有的读者问,MySQL 是怎么加锁的?这篇文章讲非唯一索引等值查询时,说「当查询的记录不存在时,加 next-key lock,然后会退化为间隙锁」。为什么上面事务 A 的 next-key lock 并没有退化为间隙锁?
如果表中最后一个记录的 order_no 为 1005,那么等值查询 order_no = 1006(不存在),就是 next key lock,如上面事务 A 的情况。
如果表中最后一个记录的 order_no 为 1010,那么等值查询 order_no = 1006(不存在),就是间隙锁,比如下图:
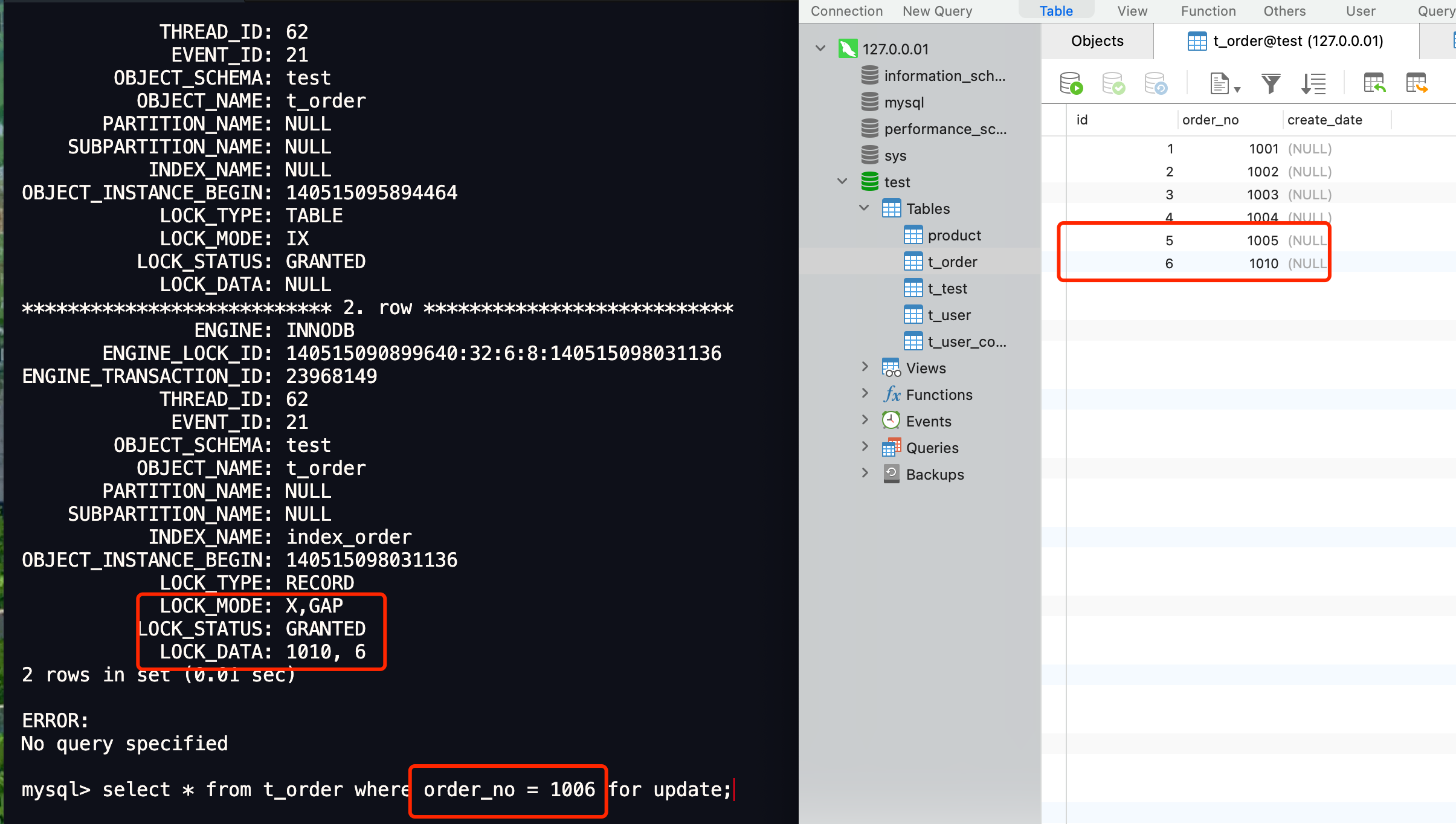
当事务 B 往事务 A next-key 锁的范围 (1006, +∞] 里插入 id = 1008 的记录就会被锁住:
Insert into t_order (order_no, create_date) values (1008, now());
因为当我们执行以下插入语句时,会在插入间隙上获取插入意向锁,而插入意向锁与间隙锁是冲突的,所以当其它事务持有该间隙的间隙锁时,需要等待其它事务释放间隙锁之后,才能获取到插入意向锁。而间隙锁与间隙锁之间是兼容的,所以所以两个事务中 select ... for update 语句并不会相互影响。
案例中的事务 A 和事务 B 在执行完后 select ... for update 语句后都持有范围为(1006,+∞]的 next-key 锁,而接下来的插入操作为了获取到插入意向锁,都在等待对方事务的间隙锁释放,于是就造成了循环等待,导致死锁。
为什么间隙锁与间隙锁之间是兼容的?
在 MySQL 官网上还有一段非常关键的描述:
Gap locks in InnoDB are “purely inhibitive”, which means that their only purpose is to prevent other transactions from Inserting to the gap. Gap locks can co-exist. A gap lock taken by one transaction does not prevent another transaction from taking a gap lock on the same gap. There is no difference between shared and exclusive gap locks. They do not conflict with each other, and they perform the same function.
间隙锁的意义只在于阻止区间被插入,因此是可以共存的。一个事务获取的间隙锁不会阻止另一个事务获取同一个间隙范围的间隙锁,共享和排他的间隙锁是没有区别的,他们相互不冲突,且功能相同,即两个事务可以同时持有包含共同间隙的间隙锁。
这里的共同间隙包括两种场景:
- 其一是两个间隙锁的间隙区间完全一样;
- 其二是一个间隙锁包含的间隙区间是另一个间隙锁包含间隙区间的子集。
但是有一点要注意,next-key lock 是包含间隙锁 + 记录锁的,如果一个事务获取了 X 型的 next-key lock,那么另外一个事务在获取相同范围的 X 型的 next-key lock 时,是会被阻塞的。
比如,一个事务持有了范围为 (1, 10] 的 X 型的 next-key lock,那么另外一个事务在获取相同范围的 X 型的 next-key lock 时,就会被阻塞。
虽然相同范围的间隙锁是多个事务相互兼容的,但对于记录锁,我们是要考虑 X 型与 S 型关系。X 型的记录锁与 X 型的记录锁是冲突的,比如一个事务执行了 select ... where id = 1 for update,后一个事务在执行这条语句的时候,就会被阻塞的。
但是还要注意!对于这种范围为 (1006, +∞] 的 next-key lock,两个事务是可以同时持有的,不会冲突。因为 +∞ 并不是一个真实的记录,自然就不需要考虑 X 型与 S 型关系。
插入意向锁是什么?
注意!插入意向锁名字虽然有意向锁,但是它并不是意向锁,它是一种特殊的间隙锁。
在 MySQL 的官方文档中有以下重要描述:
An Insert intention lock is a type of gap lock set by Insert operations prior to row Insertion. This lock signals the intent to Insert in such a way that multiple transactions Inserting into the same index gap need not wait for each other if they are not Inserting at the same position within the gap. Suppose that there are index records with values of 4 and 7. Separate transactions that attempt to Insert values of 5 and 6, respectively, each lock the gap between 4 and 7 with Insert intention locks prior to obtaining the exclusive lock on the Inserted row, but do not block each other because the rows are nonconflicting.
这段话表明尽管插入意向锁是一种特殊的间隙锁,但不同于间隙锁的是,该锁只用于并发插入操作。
如果说间隙锁锁住的是一个区间,那么「插入意向锁」锁住的就是一个点。因而从这个角度来说,插入意向锁确实是一种特殊的间隙锁。
插入意向锁与间隙锁的另一个非常重要的差别是:尽管「插入意向锁」也属于间隙锁,但两个事务却不能在同一时间内,一个拥有间隙锁,另一个拥有该间隙区间内的插入意向锁(当然,插入意向锁如果不在间隙锁区间内则是可以的)。
另外,我补充一点,插入意向锁的生成时机:
- 每插入一条新记录,都需要看一下待插入记录的下一条记录上是否已经被加了间隙锁,如果已加间隙锁,此时会生成一个插入意向锁,然后锁的状态设置为等待状态(PS:MySQL 加锁时,是先生成锁结构,然后设置锁的状态,如果锁状态是等待状态,并不是意味着事务成功获取到了锁,只有当锁状态为正常状态时,才代表事务成功获取到了锁),现象就是 Insert 语句会被阻塞。
Insert 语句是怎么加行级锁的?
Insert 语句在正常执行时是不会生成锁结构的,它是靠聚簇索引记录自带的 trx_id 隐藏列来作为隐式锁来保护记录的。
什么是隐式锁?
当事务需要加锁的时,如果这个锁不可能发生冲突,InnoDB 会跳过加锁环节,这种机制称为隐式锁。隐式锁是 InnoDB 实现的一种延迟加锁机制,其特点是只有在可能发生冲突时才加锁,从而减少了锁的数量,提高了系统整体性能。
隐式锁就是在 Insert 过程中不加锁,只有在特殊情况下,才会将隐式锁转换为显式锁,这里我们列举两个场景。
- 如果记录之间加有间隙锁,为了避免幻读,此时是不能插入记录的;
- 如果 Insert 的记录和已有记录存在唯一键冲突,此时也不能插入记录;
1、记录之间加有间隙锁
每插入一条新记录,都需要看一下待插入记录的下一条记录上是否已经被加了间隙锁,如果已加间隙锁,此时会生成一个插入意向锁,然后锁的状态设置为等待状态(PS:MySQL 加锁时,是先生成锁结构,然后设置锁的状态,如果锁状态是等待状态,并不是意味着事务成功获取到了锁,只有当锁状态为正常状态时,才代表事务成功获取到了锁),现象就是 Insert 语句会被阻塞。
举个例子,现在 t_order 表中,只有这些数据,order_no 是二级索引。
现在,事务 A 执行了下面这条语句。
# 事务 A
mysql> begin;
Query OK, 0 rows affected (0.01 sec)
mysql> select * from t_order where order_no = 1006 for update;
Empty set (0.01 sec)
接着,我们执行 select * from performance_schema.data_locks\G; 语句,确定事务 A 加了什么类型的锁,这里只关注在记录上加锁的类型。
本次的例子加的是 next-key 锁(记录锁 + 间隙锁),锁范围是(1005, +∞]。
然后,有个事务 B 在这个间隙锁中,插入了一个记录,那么此时该事务 B 就会被阻塞:
# 事务 B 插入一条记录
mysql> begin;
Query OK, 0 rows affected (0.01 sec)
mysql> insert into t_order(order_no, create_date) values(1010,now());
### 阻塞状态。。。。
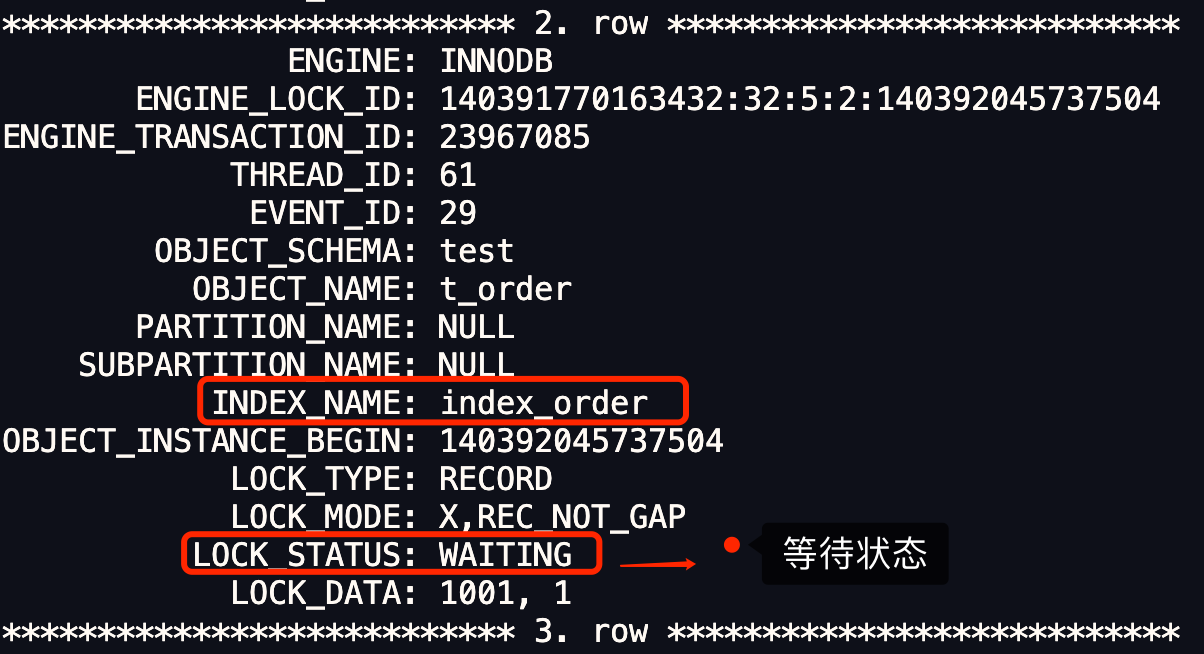
接着,我们执行 select * from performance_schema.data_locks\G; 语句,确定事务 B 加了什么类型的锁,这里只关注在记录上加锁的类型。

可以看到,事务 B 的状态为等待状态(LOCK_STATUS: WAITING),因为向事务 A 生成的 next-key 锁(记录锁 + 间隙锁)范围(1005, +∞] 中插入了一条记录,所以事务 B 的插入操作生成了一个插入意向锁(LOCK_MODE: X,INSERT_INTENTION),锁的状态是等待状态,意味着事务 B 并没有成功获取到插入意向锁,因此事务 B 发生阻塞。
2、遇到唯一键冲突
如果在插入新记录时,插入了一个与「已有的记录的主键或者唯一二级索引列值相同」的记录(不过可以有多条记录的唯一二级索引列的值同时为 NULL,这里不考虑这种情况),此时插入就会失败,然后对于这条记录加上了 S 型的锁。
至于是行级锁的类型是记录锁,还是 next-key 锁,跟是「主键冲突」还是「唯一二级索引冲突」有关系。
如果主键索引重复:
- 当隔离级别为读已提交时,插入新记录的事务会给已存在的主键值重复的聚簇索引记录添加 S 型记录锁。
- 当隔离级别是可重复读(默认隔离级别),插入新记录的事务会给已存在的主键值重复的聚簇索引记录添加 S 型记录锁。
如果唯一二级索引列重复:
- 不论是哪个隔离级别,插入新记录的事务都会给已存在的二级索引列值重复的二级索引记录添加 S 型 next-key 锁。对的,没错,即使是读已提交隔离级别也是加 next-key 锁,这是读已提交隔离级别中为数不多的给记录添加间隙锁的场景。至于为什么要加 next-key 锁,我也没找到合理的解释。
主键索引冲突
下面举个「主键冲突」的例子,MySQL 8.0 版本,事务隔离级别为可重复读(默认隔离级别)。
t_order 表中的 id 字段为主键索引,并且已经存在 id 值为 5 的记录,此时有个事务,插入了一条 id 为 5 的记录,就会报主键索引冲突的错误。

但是除了报错之外,还做一个很重要的事情,就是对 id 为 5 的这条记录加上了 S 型的记录锁。
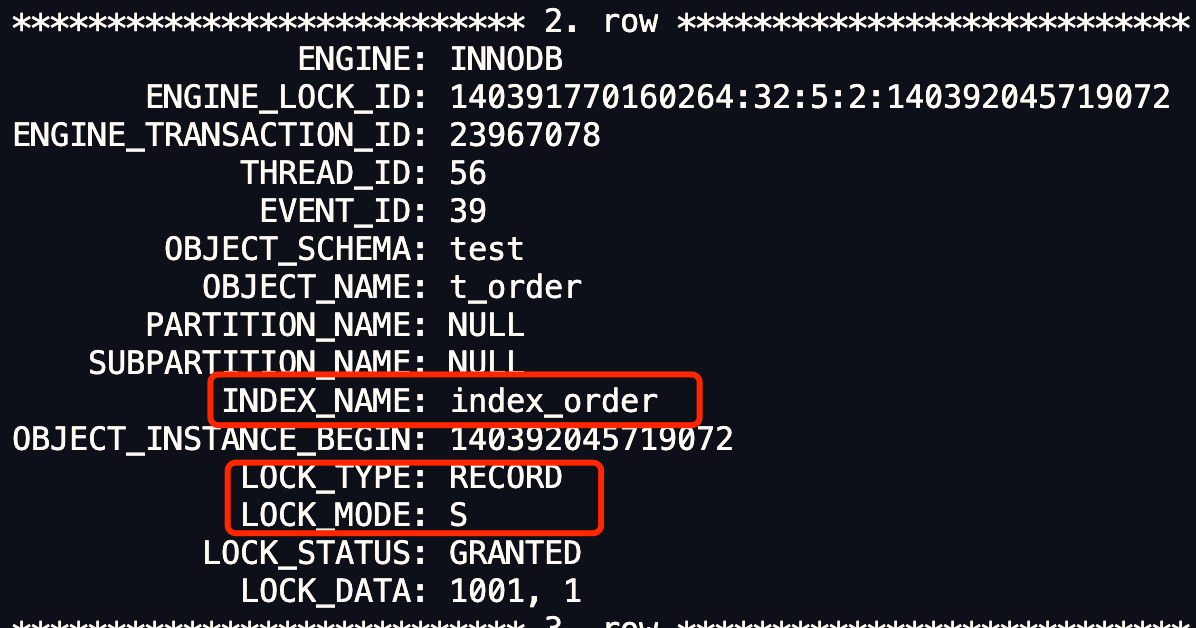
可以执行 select * from performance_schema.data_locks\G; 语句,确定事务加了什么锁。
可以看到,主键索引为 5(LOCK_DATA)的这条记录中加了锁类型为 S 型的记录锁。注意,这里 LOCK_TYPE 中的 RECORD 表示行级锁,而不是记录锁的意思。如果是 S 型记录锁的话,LOCK_MODE 会显示 S, REC_NOT_GAP。
所以,在隔离级别是「可重复读」的情况下,如果在插入数据的时候,发生了主键索引冲突,插入新记录的事务会给已存在的主键值重复的聚簇索引记录添加 S 型记录锁。
唯一二级索引冲突
下面举个「唯一二级索引冲突」的例子,MySQL 8.0 版本,事务隔离级别为可重复读(默认隔离级别)。
t_order 表中的 order_no 字段为唯一二级索引,并且已经存在 order_no 值为 1001 的记录,此时事务 A,插入了 order_no 为 1001 的记录,就出现了报错。

但是除了报错之外,还做一个很重要的事情,就是对 order_no 值为 1001 这条记录加上了 S 型的 next-key 锁。
我们可以执行 select * from performance_schema.data_locks\G; 语句,确定事务加了什么类型的锁,这里只关注在记录上加锁的类型。
可以看到,index_order 二级索引加了 S 型的 next-key 锁,范围是 (-∞, 1001]。注意,这里 LOCK_TYPE 中的 RECORD 表示行级锁,而不是记录锁的意思。如果是记录锁的话,LOCK_MODE 会显示 S, REC_NOT_GAP。
此时,事务 B 执行了 select * from t_order where order_no = 1001 for update; 就会阻塞,因为这条语句想加 X 型的锁,是与 S 型的锁是冲突的,所以就会被阻塞。

我们也可以从 performance_schema.data_locks 这个表中看到,事务 B 的状态(LOCK_STATUS)是等待状态,加锁的类型 X 型的记录锁(LOCK_MODE: X,REC_NOT_GAP)。
上面的案例是针对唯一二级索引重复而插入失败的场景。
接下来,分析两个事务执行过程中,执行了相同的 insert 语句的场景。
现在 t_order 表中,只有这些数据,order_no 为唯一二级索引。
在隔离级别可重复读的情况下,开启两个事务,前后执行相同的 Insert 语句,此时事务 B 的 Insert 语句会发生阻塞。

两个事务的加锁过程:
- 事务 A 先插入 order_no 为 1006 的记录,可以插入成功,此时对应的唯一二级索引记录被「隐式锁」保护,此时还没有实际的锁结构(执行完这里的时候,你可以看查 performance_schema.data_locks 信息,可以看到这条记录是没有加任何锁的);
- 接着,事务 B 也插入 order_no 为 1006 的记录,由于事务 A 已经插入 order_no 值为 1006 的记录,所以事务 B 在插入二级索引记录时会遇到重复的唯一二级索引列值,此时事务 B 想获取一个 S 型 next-key 锁,但是事务 A 并未提交,事务 A 插入的 order_no 值为 1006 的记录上的「隐式锁」会变「显示锁」且锁类型为 X 型的记录锁,所以事务 B 向获取 S 型 next-key 锁时会遇到锁冲突,事务 B 进入阻塞状态。
我们可以执行 select * from performance_schema.data_locks\G; 语句,确定事务加了什么类型的锁,这里只关注在记录上加锁的类型。
先看事务 A 对 order_no 为 1006 的记录加了什么锁?
从下图可以看到,事务 A 对 order_no 为 1006 记录加上了类型为 X 型的记录锁(注意,这个是在执行事务 B 之后才产生的锁,没执行事务 B 之前,该记录还是隐式锁)。

然后看事务 B 想对 order_no 为 1006 的记录加什么锁?
从下图可以看到,事务 B 想对 order_no 为 1006 的记录加 S 型的 next-key 锁,但是由于事务 A 在该记录上持有了 X 型的记录锁,这两个锁是冲突的,所以导致事务 B 处于等待状态。

从这个实验可以得知,并发多个事务的时候,第一个事务插入的记录,并不会加锁,而是会用隐式锁保护唯一二级索引的记录。
但是当第一个事务还未提交的时候,有其他事务插入了与第一个事务相同的记录,第二个事务就会被阻塞,因为此时第一事务插入的记录中的隐式锁会变为显示锁且类型是 X 型的记录锁,而第二个事务是想对该记录加上 S 型的 next-key 锁,X 型与 S 型的锁是冲突的,所以导致第二个事务会等待,直到第一个事务提交后,释放了锁。
如果 order_no 不是唯一二级索引,那么两个事务,前后执行相同的 Insert 语句,是不会发生阻塞的,就如前面的这个例子。
如何避免死锁?
死锁的四个必要条件:互斥、占有且等待、不可强占用、循环等待。只要系统发生死锁,这些条件必然成立,但是只要破坏任意一个条件就死锁就不会成立。
在数据库层面,有两种策略通过「打破循环等待条件」来解除死锁状态:
设置事务等待锁的超时时间。当一个事务的等待时间超过该值后,就对这个事务进行回滚,于是锁就释放了,另一个事务就可以继续执行了。在 InnoDB 中,参数
innodb_lock_wait_timeout是用来设置超时时间的,默认值时 50 秒。当发生超时后,就出现下面这个提示:

开启主动死锁检测。主动死锁检测在发现死锁后,主动回滚死锁链条中的某一个事务,让其他事务得以继续执行。将参数
innodb_deadlock_detect设置为 on,表示开启这个逻辑,默认就开启。当检测到死锁后,就会出现下面这个提示:

上面这个两种策略是「当有死锁发生时」的避免方式。
我们可以回归业务的角度来预防死锁,对订单做幂等性校验的目的是为了保证不会出现重复的订单,那我们可以直接将 order_no 字段设置为唯一索引列,利用它的唯一性来保证订单表不会出现重复的订单,不过有一点不好的地方就是在我们插入一个已经存在的订单记录时就会抛出异常。
最后说个段子:
面试官:解释下什么是死锁?
应聘者:你录用我,我就告诉你
面试官:你告诉我,我就录用你
应聘者:你录用我,我就告诉你
面试官:卧槽滚!
……
参考资料:
- 《MySQL 是怎样运行的?》
- http://mysql.taobao.org/monthly/2020/09/06/