4.2 如何发掘项目亮点
技术面试官主要关注简历上的两点内容:专业技能、项目经历。有些面试官喜欢问纯粹的技术问题,比如HashMap的实现、线程池的使用等等。但是资深的面试官一定结合项目提问,穿插基础技术问题。如果不能说出项目的亮点或难点,无法体现解决问题的能力,面试官就不会给高分。
大部分人不在大厂工作或者处在大厂的边缘项目,经常抱怨自己的项目平平无奇。其实,只要深度挖掘总能找到一些亮点,建议从以下3个方面入手:
- 系统设计:结合业务需求,设计低成本高效的解决方案
- 性能调优:解决性能瓶颈,提高系统总体吞吐量和稳定性
- 故障排除:快速准确的处理线上故障,并且进行故障复盘
在日常开发中就要总结项目的亮点,早点为面试存储一些材料。描述项目亮点要注意技巧,把面试官引入自己熟悉的知识点上去,看看下面的模拟对话:
面试官:这个项目有什么亮点,或者有哪些让你印象深刻的东西?
候选人:我解决了一个核心接口的性能瓶颈,接口耗时从500 ms降低到100 ms,解决的过程是这样的......
面试官:你的简历上提到采用DDD进行了系统设计,能够详细说一下吗?
候选人:我对DDD的理解比较粗浅,但是参与过分库分表的大活儿,您愿意听我说一下吗?
面试官:可以,请说吧!
以下内容以Java技术体系为例,罗列了一些项目中值得说一说的亮点。
1 系统设计
架构师负责的系统设计一般维度较高,服务整个技术部门。业务部门开发复杂需求时,也要权衡研发成本、系统扩展性等因素,设计出低成本高效的方案。
1.1 运用设计模式
大部分Java项目都是基于Spring Boot 构建,只要按照规约填充业务代码,不需要运用太多设计模式,但是部分场景可能用到单例模式、外观模式、责任链模式。
- 单例模式(Singleton Pattern)
单例模式确保一个类只有一个实例,并提供全局访问点,常常用于管理受限的资源,使用场景如下:
(1)数据库连接池:单例模式确保在只有一个数据库连接池实例,避免出现重复连接的问题。
(2)日志处理器:在大多数情况一个日志处理器实例就足够了,单例可以减少资源的浪费。
(3)性能管理器:单例模式可以确保性能管理器的整个生命周期中只有一个实例运行。
(4)线程池:采用单例模式创建线程池,可以避免内存使用过高。
- 外观模式(Facade Pattern)
外观模式为子系统定义了一个统一的接口,客户端无须关心子系统的工作细节,通过外观角色即可调用相关功能,简化了内外通信的调用规则。典型的外观角色代码:
public class Facade
{
private SubSystemA obj1 = new SubSystemA();
private SubSystemB obj2 = new SubSystemB();
private SubSystemC obj3 = new SubSystemC();
public void method()
{
obj1.method();
obj2.method();
obj3.method();
}
}
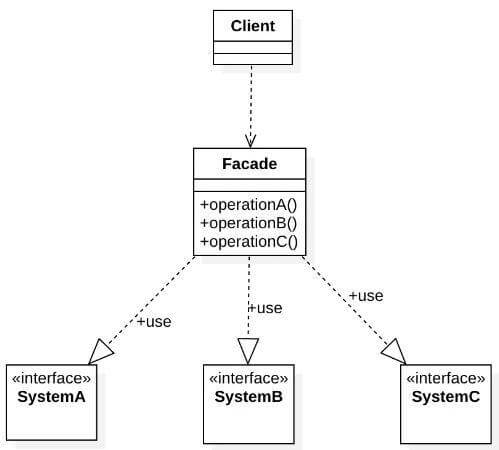
外观模式
外观模式的缺点是违背了“开闭原则“,增加新的子系统需要修改外观类或客户端的代码。
- 责任链模式(Responsibility Chain Pattern)
责任链模式指责任请求沿着处理者链前进, 每个处理者要么处理请求,要么传递给链上的下个处理者。
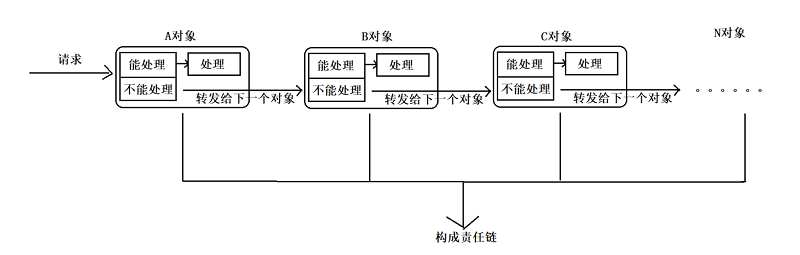
责任链模式
责任链的使用场景有3个:
- 流程判断:实现多用户系统的权限控制,比如先校验用户身份,再校验功能授权。
- 业务审批:实现业务流程的层层审批,比如审批经过总经理、人事经理、项目经理。
- 过滤器:实现Web请求过滤,比如编码过滤、判断用户的登陆状态,典型的案例是Java Servlet的过滤器实现。
1.2 分布式ID解决方案
在分布式系统中有多个计算节点,不能依赖单节点生成生成唯一标识符,要保证在全局范围内每个ID是唯一的,这就是分布式ID。分布式ID的需求有5点:
- 全局唯一:无论哪个节点生成ID,都保证全局范围内唯一。
- 趋势递增:分布式ID最终要写入数据库,趋势递增的特性可以保证数据库查询效率。
- 业务含义:分布式ID携带业务含义,比如创建时间、业务类型等。
- 高性能:生成效率高,不能存在严重的性能瓶颈。
- 高可用性:个别节点宕机后,依然能够获取到ID。
常见的分布式ID生成策略有:UUID、号段模式、雪花算法、基于Redis的ID生成方案等。具体选择哪种方案,需要根据系统的实际需求来决定。
- UUID
UUID(Universally Unique Identifier)是指在一台机器上生成的数字,保证对在同一时空中的所有机器都是唯一的。算法用到了以太网卡地址、纳秒级时间、芯片ID码和随机数字。
30c0c01c-2b6e-4e91-8de1-5e8a06ea214a
UUID的优点是生成效率高、唯一性高,一般适用仅做唯一标识的场景,如:MQ消息的ID,分布式追踪的Trace ID等等。UUID不适合做入库的业务主键,有几个原因:
(1)存储成本高: UUID是36个字节的字符串,部分场景需要短一点。
(2)信息不安全: 基于MAC地址生成的UUID算法暴露MAC地址。
(3)没有趋势递增: 关系性数据库希望主键越短越好,无序性也会造成索引数据位置频繁变动,影响插入和查询性能。
- 号段模式
号段模式是指每次从数据库取出一个号段范围,加载到服务内存中,调用方在这个范围递增取值。例如 (1,1000] 代表1000个ID,具体的业务服务将本号段生成1~1000的自增ID,数据表结构如下:
CREATE TABLE id_generator (
id int(10) NOT NULL,
max_id bigint(20) NOT NULL COMMENT '当前最大id',
step int(20) NOT NULL COMMENT '号段的长度',
biz_type int(20) NOT NULL COMMENT '业务类型',
version int(20) NOT NULL COMMENT '乐观锁版本号',
PRIMARY KEY (`id`)
)
等这批号段ID用完,再次向数据库申请新号段,对max_id字段做一次update操作,新的号段范围是 (max_id ,max_id + step)。多业务端可能同时操作,通常采用乐观锁方式更新。
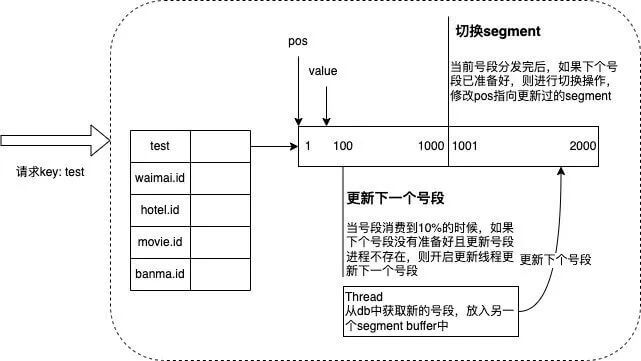
号段模式
号段模式的高可用依赖数据库的高可用架构,当应用重启的时候部分ID会被浪费,不过这是小问题。
- Redis INCR
Redis INCR 命令用于对存储在 Redis 中的键进行自增操作。它适用于存储为整数的值,每次执行 INCR 命令,键的值将会增加1,并返回自增后的值。如果键不存在,则会创建一个新的键,并将其初始值设置为0。演示命令如下:
INCR key
借助 Redis 极强的并发特性,这个方案既能够实现高并发又能保证单调递增。Redis主从之间是异步复制的,如果Master宕机之前,还有数据没有同步到Slave,而 Slave被选举为 Master,就会出现ID重复的问题。
- 雪花算法
雪花算法是Twitter开源的分布式ID生成算法,以划分命名空间的方式将64bit位分割成了多个部分,每个部分都有具体的不同含义,如下所示:
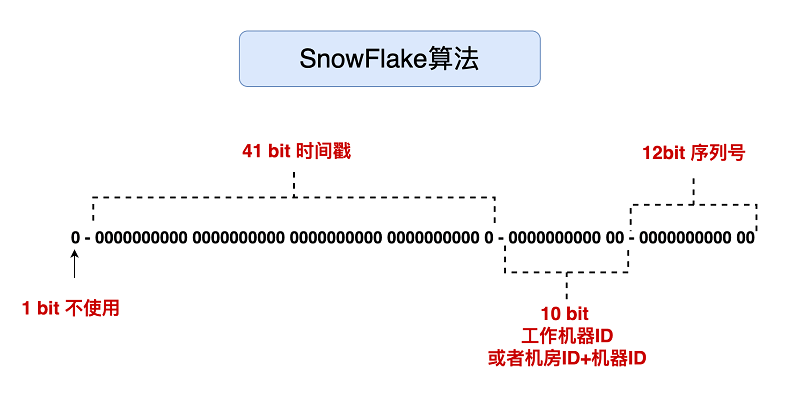
第一部分: 占用1bit,第一位为符号位
第二部分: 41位的时间戳,41bit位可以表示241个数,每个数代表的是毫秒,那么雪花算法的时间年限是(241)/(1000×60×60×24×365)=69年
第三部分: 10bit表示是机器数,即 2^ 10 = 1024台机器,通常不会部署这么多机器
第四部分: 12bit位是自增序列,可以表示2^12=4096个数,一秒内可以生成4096个ID,理论上snowflake方案的QPS约为409.6 w/s。
雪花算法强依赖机器时钟,如果机器上时钟回拨会导致发号重复,通常通过记录最后使用时间处理该问题。
1.3 实现接口幂等性
接口幂等性,是指多次请求某一个资源对于资源本身应该具有同样的结果。业务开发中,经常会遇到重复提交的情况,比如用户在APP上连续点击了多次提交订单,后台应该只产生一个订单。实现接口幂等性有很多种方案,不同的方案的成本不同,要根据实际情况实施。
- 数据库唯一索引
唯一索引适用于插入数据时的幂等性,保证一张表中只能存在一条符合唯一索引的记录。唯一索引可以是主键,也可是组合唯一索引。组合唯一索引是将重复的条件判定放在了数据库层。
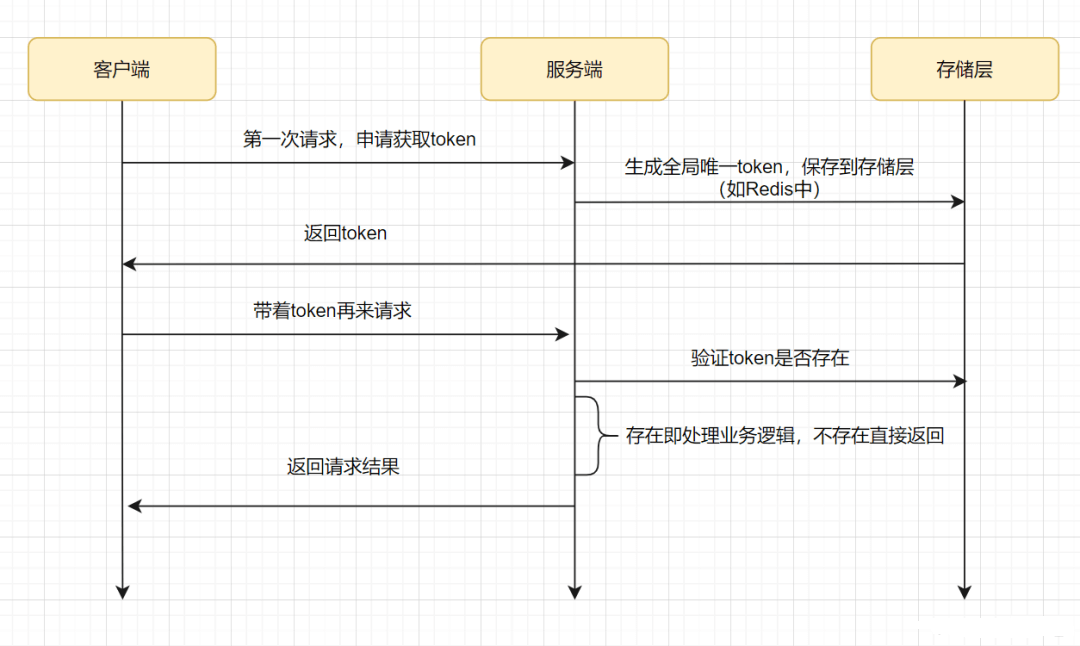
- 防重令牌
调用方在调用接口的时候先向后端请求一个全局 Token,请求的时候携带这个全局 Token 一起请求(Token 最好将其放到 Headers 中),后端需要对这个 Token 作为 Key,用户信息作为 Value 到 Redis 中进行键值内容校验,如果 Key 存在且 Value 匹配就执行删除命令,然后正常执行后面的业务逻辑。
2 性能调优
2.1 降低接口耗时
过早优化是万恶之源,一定要优化接口耗时的话,要估算收益是否大于成本,具体的优化步骤:
(1)接口调研:根据日志确定耗时高是常态,不是偶发性。结合监控系统、链路跟踪系统等工具定位性能瓶颈。
(2)制定方案:结合调用方的需求和开发人员的经验确定优化方案,比如调用方希望耗时在3秒内或者接受异步通知。
(3)实施方案:通过代码重构、引入中间件等方式改造接口,最好包含灰度方案或者动态切换新老逻辑的开关。
常规业务系统譬如电商、物流都属于数据密集型系统,即数据是系统成败的决定性因素,包括数据的规模、数据的复杂度、数据产生与变化的速率。这类系统对IO的操作频率远远高于CPU,减少IO操作、提高CPU利用率是性能优化的大方向。排除掉网络质量问题,导致接口性能问题的原因很多。
- 数据库读写性能差
系统发展到一定的阶段,单实例的数据库一定无法支撑高并发的读写,优先考虑的应该是索引优化和冷数据归档,分库分表是最后的大招。
(1) 冷数据归档:将用户不太关注的历史数据从单表中迁移走,前端提示用户只提供最近N个月数据。保证每个表的数据在一千万左右,查询耗时在0.5秒以内。
(2)索引优化:索引可以大大提高数据的查询速度。索引优化需要重点关注索引失效的原因。如果单表的数据量过大,优化索引也无法改善性能。
(3) 数据缓存:读多写少、弱实时性的场景,尝试缓存数据。缓存的介质常常是内存,查询速度远高于数据库的磁盘,提升性能的效果非常明显。常用分布式缓存组件是Redis,二级缓存组件有Guava Cache、Caffeine、Encache,Spring Cache可以集成使用这三者。
- 业务逻辑复杂
(1)异步调用接口:接口异步调用是最直接的方案,耗时都在网络请求和RPC连接上,耗时肯定在1秒内。由于无法同步返回数据,调用方要异步处理结果,增加了系统复杂性。
(2)异步处理部分业务:如果不能接受整个接口异步调用,考虑将部分非核心流程异步执行。比如下单接口包含查库存、生成订单、发送短信三个步骤,发送短信不是核心流程,可以改为发送MQ消息触发短信,能省下一点耗时。
(3)多业务并行处理:在满足业务逻辑的前提下,将没有关联的步骤由串行改为并行执行。比如有A和B两个步骤,分别耗时200ms和100ms,并行执行后最大耗时就是A的200ms。以下代码演示了Java语言的并行处理,将“查询满100减10信息”和“查询可用优惠券信息”的结果汇总返回给接口。
(4)调整业务流程:如果从技术角度上找到更好的方案,可以尝试调整业务流程。将一个接口做完的事情,拆成两三个接口来做,每个接口的耗时自然就减少了。再通过校验业务数据,保证拆分后的接口的顺序调用。
2.2 系统限流策略
任何系统的性能都有一个上限,当并发量超过这个上限之后,可能会对系统造成毁灭性地打击。因此必须限制并发请求数量不能超过某个阈值,限流就是为了完成这一目的。
- 计数器算法
规定在1分钟内访问接口次数不能超过1000个,设置一个计数器,对固定时间窗口1分钟进行计数,每有一个请求,计数器就+1,如果请求数超过了阈值,则舍弃该请求,当时间窗口结束时,重置计数器为0。

计数器算法
计数器算法虽然简单,但是有临界问题。假设有一个用户在0:59时,瞬间发送了1000个请求,并且1:01又发送了1000个请求,那么其实用户在 2秒里面,瞬间发送了2000个请求。用户在时间窗口的重置节点处突发请求, 可以瞬间超过速率限制,压垮应用。
- 滑动窗口算法
滑动窗口算法解决了计数器算法的缺点。计数器的时间窗口是固定的,而滑动窗口的时间窗口是动态的。
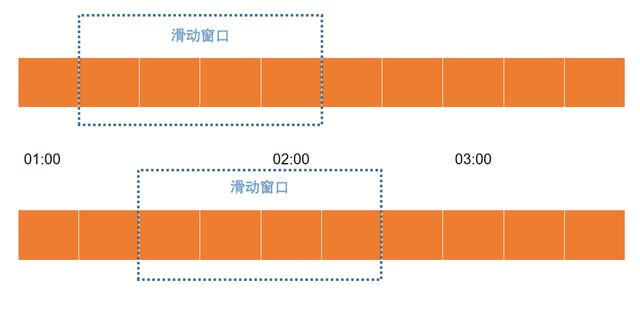
滑动窗口算法
橙色的矩形框表示一个时间窗口,一个时间窗口就是一分钟。滑动窗口划成了4格,每格代表的是15秒钟。每过15秒钟,时间窗口就会往右滑动一格。每一个格子都有自己独立的计数器,比如当一个请求在0:30秒的时候到达,那么0:30~0:44对应的计数器就会加1。那么滑动窗口怎么解决刚才的临界问题的呢?0:59到达的1000个请求落在格子中,而1:01到达的请求会落在后面的格子中。当时间到达1:00时,窗口会往右移动一格,此时时间窗口内的总请求数量一共是2000个,超过了限定的1000个,此时能够检测出来触发限流。
- 漏桶算法
想想一个场景:一个水桶的桶底下有一个小孔,水以固定的频率流出,水龙头以任意速率流入水,当水超过桶则”溢出“。
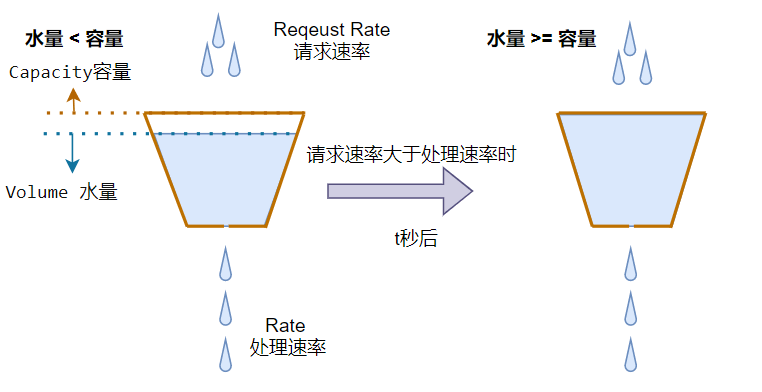
漏桶算法
漏桶算法保证了固定的流出速率,这是优点也是缺点。始终恒定的处理速率有时候并不一定是好事情,对于突发的请求洪峰,在保证服务安全的前提下,应该尽最大努力去响应,这个时候漏桶算法显得有些呆滞,最终可能导致水位溢出,丢弃请求。
- 令牌桶算法
很多限流场景除了限制数据的平均传输速率,还要允许某种程度的突发传输。这时候漏桶算法可能就不合适了,令牌桶算法更为适合。令牌桶算法的原理是系统以恒定的速率产生令牌,然后把令牌放到令牌桶中,令牌桶有一个容量,当令牌桶满了的时候,再向其中放令牌,那么多余的令牌会被丢弃;当想要处理一个请求的时候,需要从令牌桶中取出一个令牌,如果此时令牌桶中没有令牌,那么则拒绝该请求。
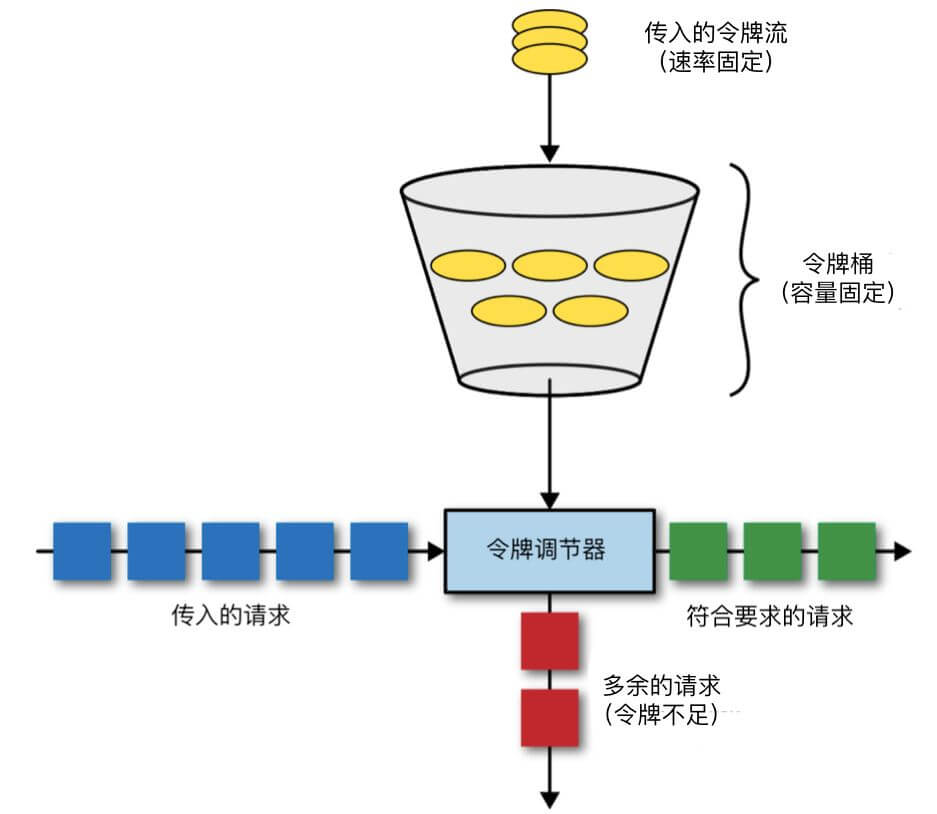
令牌桶算法
令牌桶算法的缺点是,需要根据以往的系统性能、用户习惯等判断令牌数量和生成速度,难以预知实际的限流数。
3 故障排除
3.1 Java微服务OOM
在生产环境中,JVM内存溢出是很常见的故障,通常分5类错误:
- 堆溢出 java.lang.OutOfMemoryError: Java heap space
- 栈溢出 java.lang.StackOverFlowError
- 元信息溢出 java.lang.OutOfMemoryError: Metaspace
- 直接内存溢出 java.lang.OutOfMemoryError: Direct buffer memory
- GC超限 java.lang.OutOfMemoryError: GC overhead limit exceeded
造成JVM内存溢出通常有4个原因:
- 加载太多数据进入内存,如一次从数据库取出过多数据
- 资源使用之后没有及时关闭,相关对象无法被GC回收
- 代码中存在死循环或循环产生过多重复的对象实体
- JVM启动参数设置不当,内存分配过小
在JVM启动之前,配置OOM的dump日志文件输出路径,如下所示:
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/jvm/outofmemory/ -Xms1024m -Xmx1024m
当发生OOM时,JVM在路径 /usr/jvm/outofmemory/ 输出名为 java_pidXXXX.hprof 的文件。使用JProfiler工具分析该文件,就可以定位有问题的源码位置。
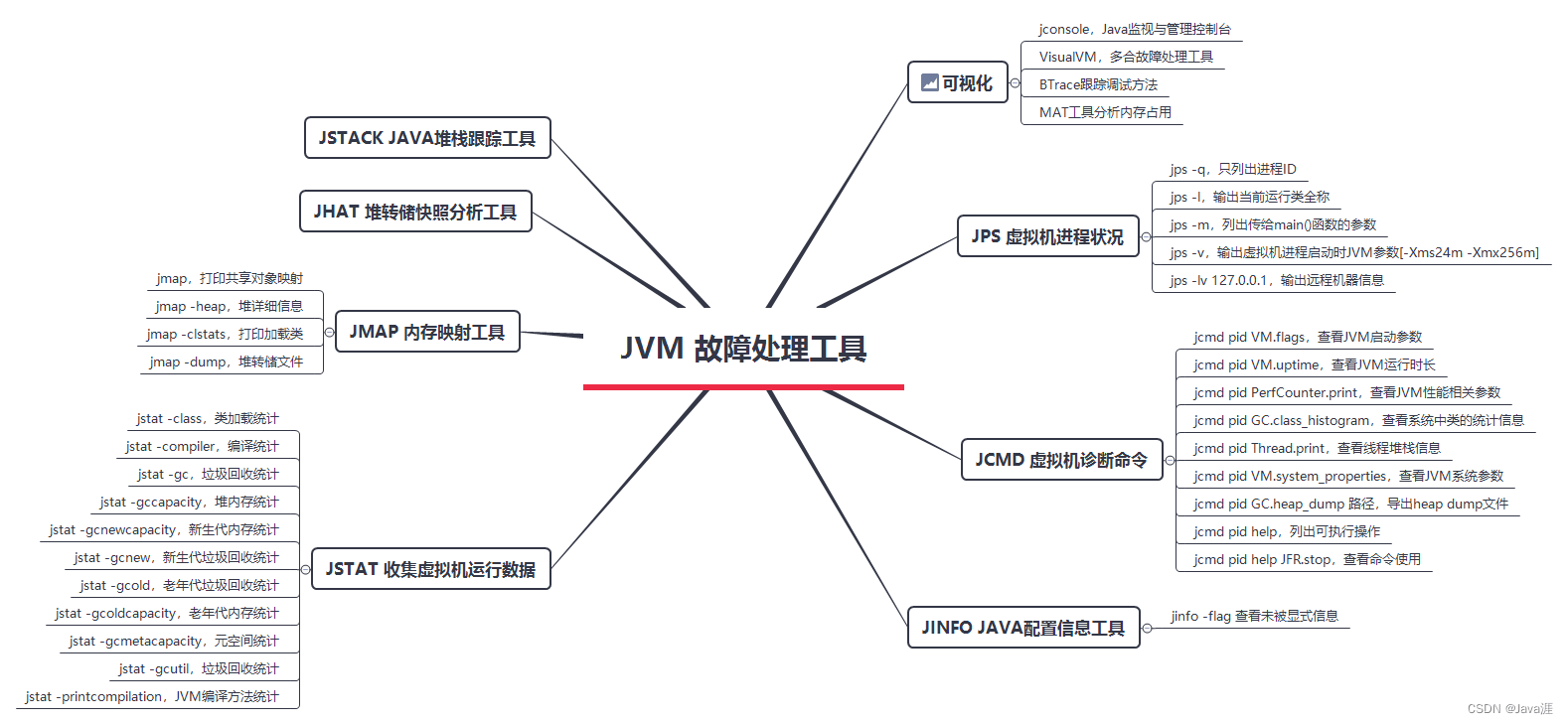
JVM工具
3.2 RocketMQ消息堆积
当消息消费者的处理能力跟不上消息产生的速度时,消息会积压在消息队列中,这就是MQ消息堆积。一旦出现消息堆积,直接的影响是新消息无法进入队列,用户的反应是系统有延迟,体验不好。
通过RocketMQ的管理控制台可以查阅 topic 的消息堆积情况,如下图所示:
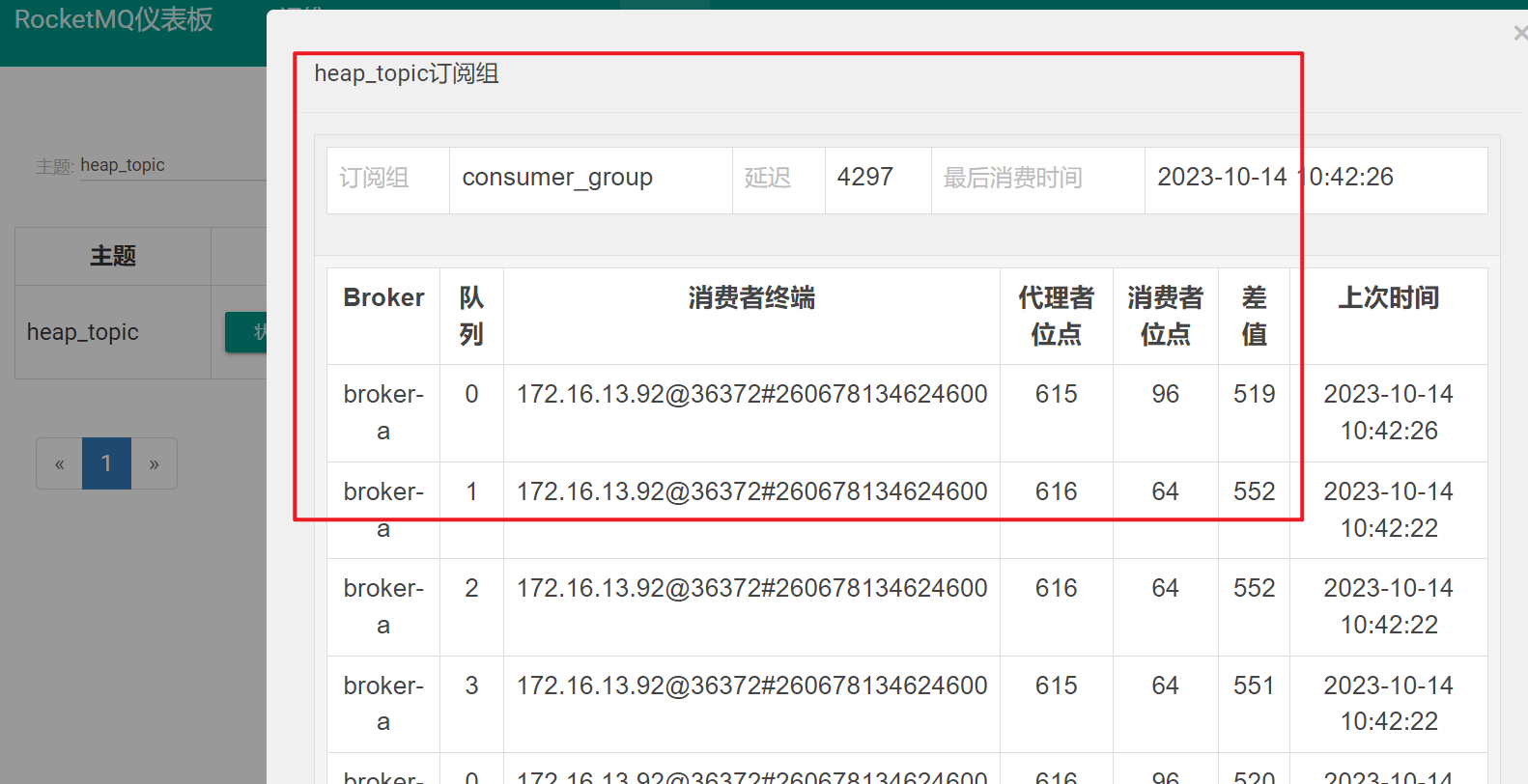
RocketMQ控制台
业务系统需求不一样,但是造成消息堆积的原因主要有四点:
- (1)新上线的消费者代码有问题,无法正常消费消息。
- (2)消费者实例宕机,或者无法同Broker建立连接。
- (3)生产者短时间内推送大量消息到Broker,消费者消费能力不足。
- (4)生产者没有感知Broker消费堆积,持续向Broker推送消息。
无论属于哪一种情况,针对MQ的监控和预警是首要工作,当消息堆积达到一定阈值时,发出预警及时处理。针对以上四点原因,解决方案是:
- (1)灰度发布:新功能上线前,选取一定比例的消费实例做灰度,若出现问题及时回滚;若消费者消费正常,平稳运行一段时间后,再升级其它实例。如果需要按规则选出一部分账号做灰度,则需要做好消息过滤,让正常消费实例排除灰度消息,让灰度消费实例过滤出灰度消息。
- (2)多活:极端情况下,一个IDC内消费实例全部宕机时,让其他IDC内的消费实例正常消费消息。若一个IDC内Broker全部宕机,生产者要将消息发送至其它IDC的Broker。
- (3)增强消费能力:增加消费者线程数或增加消费者实例个数。增加消费者线程数要注意消费者及其下游服务的消费能力,上线前就要将线程池参数调至最优状态。增加消费者实例个数,要注意Queue数量,消费实例的数量要与Queue数量相同,如果消费实例数量超过Queue数量,多出的消费实例分不到Queue,只增加消费实例是没用的,如果消费实例数量比Queue数量少,每个消费实例承载的流量是不同的。
- (4)熔断与隔离:当一个Broker的队列出现消息积压时,要对其熔断隔离,将新消息发送至其它队列,过一定的时间,再解除其隔离。